Des articles, livres ou numéros de revues se sont penchés sur le Big Data depuis plus de dix ans, sous un angle parfois très critique1, souvent interdisciplinaire2, avec parfois une dimension historique3. Certaines publications s’interrogent sur la pertinence de la définition du terme : alors même que la mise à disposition de données de plus en plus abondantes risque d’entraîner de profonds changements disciplinaires et méthodologiques4, d’autres tentent une vue plus générale sur l’ensemble du champ des sciences sociales5 et les usages par ces dernières des différents types de données6.
Les réflexions sur l’espace-temps à l’ère du Big Data restent cependant à approfondir. Longtemps figurée sous la forme de deux entités distinctes et immuables, la représentation de l’espace-temps comme un ensemble indissociable au début du XXe siècle a profondément influencé les écoles de pensée en sciences humaines et sociales (SHS). Cette conception bergsonienne d’un espace-temps à vitesse et géométrie variables continue de nourrir les réflexions historiques, comme en attestent les travaux de Reinhart Koselleck7, François Hartog8 ou du philosophe Hans Ulrich Gumbrecht9 et peut être repensée sous l’effet du recours aux données massives et éphémères que sont les données disponibles sur le Web et les réseaux sociaux numériques (RSNs). Ces dernières sont indéniablement des sources pour l’histoire sociale et culturelle, présentant des entrelacs de temps perçus et vécus, à différentes échelles, dans tous les espaces géographiques.
Comme l’archive papier, les traces numériques peuvent permettre l’élaboration d’une chronologie précise à partir d’un événement, à l’instar de la COVID-19 ou des attentats de 2015 en France. Elles peuvent également dessiner des temps longs et alimenter une histoire sérielle à partir de sujets sociaux et économiques du temps présent (précarité, égalité homme/femme…). Elles saisissent de facto des « vibrations10 », des tendances et des inscriptions spatiales11, comme en témoignent certaines collectes récentes de plusieurs millions de tweets12, à partir de méthodes d’archivage spécifiques abordées dans cet article.
Celui-ci propose en effet de penser les différents jeux d’échelle et de temporalités qui opèrent au sein de ce patrimoine nativement numérique – en particulier des RSNs et du web archivé, en trois temps : celui de la collecte d’abord, qui pose des enjeux de préservation, sélection, curation, représentativité et accès ; celui des données ensuite, qui présentent des entrelacs spatio-temporels complexes ; celui de la recherche enfin, qui implique une herméneutique numérique appropriée et des outils computationnels comme intellectuels pour les aborder. Cette exploration spatio-temporelle tout au long de la chaîne de préservation et d’analyse des données massives doit permettre de saisir les conséquences de l’archivage massif des données sur la mémoire, l’histoire et le métier d’historien, ainsi que les asymétries et distorsions entre la portée théorique du Big Data (de la milliseconde à la longue durée, du mètre au globe) et sa portée pratique (inégalités régionales dans les collectes, silos entre collections, bruits et silences au sein des archives, etc.).
Espace et temps des collectes
Les traces numériques recueillies sur les sites web et les RSNs, qu’elles soient sous la forme d’écrits, d’images, de vidéos ou de métadonnées, constituent des sources de plus en plus convoquées dans les travaux de recherche en SHS. Les historiens s’en sont également emparés dans des études portant sur des dimensions mémorielles en ligne d’événements13 ou l’histoire du numérique14, à partir de collectes institutionnelles15 ou de collectes entreprises individuellement16.
Étudier des sources « nativement numériques » implique une réflexion sur les paradigmes et cadres sociaux entourant ces données. Si Franck Ghitalla17 ou Mark Graham18 ont proposé une cartographie du Web à partir de sa structure technique, d’autres ont utilisé le Web non comme un objet mais comme une variable supplémentaire à leur sujet d’étude. La géopolitique et les études stratégiques repensent ainsi le Web comme un « cyberespace » ou une « datasphère » qui prolonge les territoires physiques afin de comprendre les dynamiques spatiales et les conflits contemporains, de redéfinir des frontières et mettre en lumière des acteurs inconnus jusqu’alors, sous la forme de réseaux culturels, politiques ou encore religieux pluriels et inexplorés. Des études ont par exemple montré la centralité des RSNs dans les mobilisations populaires des années 2010 autour de nouveaux types d’acteurs comme les influenceurs, ou de nouveaux lieux de pouvoir comme les places19. Les traces laissées sur Twitter et Facebook au moment du mouvement vert de 2009 en Iran et des printemps arabes de 2011 en Égypte, en Tunisie et en Syrie, ont permis de démontrer le rôle fondamental (et les limites) de certaines plateformes dans l’organisation des mouvements contestataires20 et la diffusion d’informations au monde entier, depuis des espaces où la liberté de parole est pourtant limitée.
La mainmise de plus en plus affirmée d’acteurs privés (GAFAMI21 notamment) sur Internet et le Web depuis le début des années 2010 a toutefois des conséquences directes sur la pérennité et l’accessibilité des traces numériques. L’idée d’un Internet « souverain » est par ailleurs devenue un moyen de contrôle des idées et des mouvements de populations à des fins politiques, comme en témoignent la mise en place du Runet en Russie depuis 2019, la construction de « routes de la soie numériques » par la Chine en 2015 ou encore la validation d’un « plan de protection » du Web iranien en 2021. Les coupures ponctuelles des couches basses d’Internet à des fins répressives, comme au Kazakhstan en janvier 2020 ou en Birmanie en février 2021, tout comme des cas de blocage d’Internet Archive et de l’accès à ses archives du Web (en 2017 en Jordanie par exemple) ont des conséquences directes sur la production, la préservation et l’accessibilité des données. Il faut ainsi considérer des asymétries, notamment pour l’étude des régions non-occidentales22, déjà pénalisées par l’impossibilité d’accéder au terrain23. Des initiatives françaises tentent de faire de certaines zones de conflits un terrain de recherche multidisciplinaire, grâce à la disponibilité des traces numériques. L’ANR SHAKK24 a pour objectif de reconstruire les événements syriens depuis 2011 hors du terrain étudié. Ce projet pluridisciplinaire ambitionne de dégager les nouvelles frontières de la Syrie, ainsi que l’évolution des pouvoirs et acteurs en place dans le pays. L’équipe convoque des données du Web, vidéos, photographies ou commentaires publiés par des manifestants, des activistes ou encore des combattants. Dans un même souci de pallier un terrain inaccessible, l’ERC Off-Site25 propose depuis 2018 une étude ethnographique sur la violence d’État durant les années Khomeini en Iran (1979-1988) à l’aide des sources alternatives (counter-archives)26. Malgré le caractère novateur de ces projets ou d’une méthodologie de la cartographie appliquée au cyberespace telle que le propose le laboratoire de géopolitique GEODE, à partir de l’exemple russe27, il reste encore beaucoup à faire et à partager sur la méthodologie de ces terrains numériques.
Le déplacement de la recherche vers des structures dématérialisées n’est par ailleurs pas une réponse absolue : tous les pays ne disposent pas d’archivage institutionnel du Web, tandis qu’Internet Archive ne peut couvrir également toutes les régions du globe. De nombreuses données ne sont ainsi pas sécurisées et restent périssables : les suppressions de publications et de commentaires, les fermetures de compte, les changements de logiciel28 et même les incendies de datacenters ou serveurs constituent autant de micro-événements dramatiques pour la préservation des données.
L’oubli, l’irrégularité de collectes ou le manque de pérennité de certaines traces invitent l’historien à se faire l’archiviste de ses propres données, parfois en anticipant des projets futurs. Cette problématique de l’anticipation est bien connue des chercheurs travaillant sur des régions à risque, et qui manipulent des données dispersées sur une multitude de plateformes mouvantes et soumises au risque de potentielles fermetures de domaines internet et aux enjeux de la cybergouvernance29.
Face à l’urgence, les institutions (bibliothèques en charge du dépôt légal, fondation comme Internet Archive, etc.) lancent aussi des collectes spéciales, par exemple lors d’attentats ou de la pandémie de la COVID-19. L’espace-temps des collectes institutionnelles est en effet à la fois régulier et toujours susceptible d’être bousculé par l’actualité30. De nombreuses institutions ont mis en place des collectes annuelles ou bi-annuelles pour les sites relevant de leur périmètre, qu’elles ne pourraient pas préserver quotidiennement, alors que l’on parle de millions d’URL et noms de domaine. Des collectes plus régulières, voire quotidiennes, sont prévues sur des sites web spécifiques, par exemple de presse à la Bibliothèque nationale de France (BnF). Certains événements, comme les élections, font l’objet de collectes spéciales anticipées. Enfin des collectes liées à un événement inattendu peuvent bousculer l’archivage du Web, en appelant à une réaction immédiate. Dès 2015, la BnF et l’Ina, confrontés aux multiples expressions numériques que suscitent les attaques terroristes en France, mettent en place des collectes d’urgence31. L'événement inattendu implique un archivage qui doit suivre au plus près les traces numériques sans pouvoir totalement les anticiper, que ce soit en termes de tendances ou de temporalités : la collecte crée ainsi une archive vivante (living archive32), qui s’enrichit au fil des jours de nouveaux sites web (dans le cas de la crise de la COVID-19), et un hashtag peut prendre le pas sur un autre (dans le cas des attentats du Bataclan, le hashtag « tirs » est employé avant que l’on parle d’attentat). Comme l’explique Thomas Drugeon (Ina) au sujet du 13 novembre 2015 : « Les hashtags étaient plus éparpillés en novembre, en janvier presque tout était concentré sur le hashtag #jesuischarlie. En novembre ressortent au moins cinq hashtags et on discerne des mouvements, des cycles également, par exemple jour/nuit en rapport avec le décalage horaire à l’international33 ».
La collecte d’urgence soulève d’autres problèmes de temporalités : quand commencer l’archivage et quand l’arrêter, lorsque la crise s’installe, par exemple dans le cas de la COVID-19 ? Comment gérer les vagues qui se succèdent et les rendre compatibles avec les autres missions des équipes, le budget et les contraintes techniques et politiques de préservation34 ? Comme en témoigne Ben Els, archiviste du Web à la Bibliothèque nationale du Luxembourg : « Nous avons commencé le 16 mars 2020, et il est difficile de dire quand nous nous arrêterons. Il s'agit plutôt d’une question budgétaire. […] J’ai beaucoup de téraoctets à ma disposition, mais nous ne mettrons pas forcément 5 téraoctets de plus35 ». À des collectes COVID qui peuvent s’arrêter dès 2020 (ce qui ne signifie pas que les archives du Web sont ensuite muettes, puisqu’une collecte régulière comme celle dédiée à l’Actualité à la BnF va inclure de nombreux éléments liés à la crise sanitaire) répondent au contraire des archives qui continuent de s’enrichir, par exemple à l’Ina, au fil des échos que trouvent la référence aux attentats contre Charlie Hebdo sur Twitter, que ce soit lors des attentats du Bataclan ou de Nice ou des commémorations et procès qui reconvoquent les hashtags de 2015.
L’exhaustivité est impossible : les archivistes en sont conscients, et essaient de viser une forme de représentativité en documentant parfois les données manquantes, comme à l’Ina pour sa collecte des attentats via l’API36 de Twitter. La représentativité passe aussi par le soin porté aux traces locales ou régionales, comme dans la collection COVID-19 de la BnF. Une analyse de ses données dérivées permet d’identifier de nombreux sites web régionaux. Comme l’explique Alexandre Faye (BnF), la sollicitation des différents départements de la BnF et des correspondants DLWeb37 notamment en région, fait que « la moitié des contenus sélectionnés durant le confinement ont un mot clé géographique qui indique que le contenu est en lien avec un territoire précis38 ».
Certaines régions du monde peuvent connaître une moindre attention : l’épidémie d’Ebola n’a pas d’équivalent d’archivage par rapport à la crise du COVID, ce qui ne s’explique pas uniquement par le caractère plus récent de la seconde. On signalera toutefois les efforts collectifs au sein d’Archive-It, lié à Internet Archive, pour documenter par exemple le tremblement de terre en Haïti en 201039.
Enfin, des espaces numériques ne sont pas archivés, ou de manière très ponctuelle : outre Periscope, utilisé au moment des attentats du Bataclan, Instagram ou TikTok ne sont guère archivés, tandis que Vine a disparu et que Telegram révèle son importance dans la guerre en Ukraine, sans bénéficier de réelle politique d’archivage. On notera toutefois dans le cas du conflit ukrainien la vive réactivité à l’égard du patrimoine nativement numérique, avec le lancement de l’initiative participative SUCHO, Saving Ukrainian Cultural Heritage Online40. Malgré cet exemple extraordinaire, bien des espaces sont et seront oubliés par les archivages d’urgence, alors que les internautes déploient leur inventivité sous forme de mèmes sur les RSNs ou encore de commentaires dans les espaces d’avis des restaurants russes, pour essayer d’alerter la population sur les horreurs de cette guerre41. L’archive est toujours lacunaire, mais ici se joue aussi une partie de la guerre : l’oubli est aussi conséquence de rapports de forces, y compris en conflit armé42.
Malgré des millions de données collectées, de fortes asymétries et des silences traversent les espaces et temps des collectes, qui se manifestent également au sein des collections.
Espace et temps au sein des collections
Les Big Data en histoire ne correspondent pas tout à fait à la définition originelle qui fait référence aux « 3V43 » : Vélocité, Volume et Variété des données44. En effet, les données passées font, en toute logique, preuve d’un manque de vélocité, c’est-à-dire de renouvellement constant et en temps réel du corpus (à l’exception des études mémorielles, à l’image du corpus déjà évoqué des attentats qui continue d’évoluer sous l’effet de la réutilisation d’hashtags antérieurs). Toutefois, les deux autres V – volume et variety – concernent directement les historiens et historiennes. Ils permettent de travailler sur l’espace et le temps avec des outils de lecture distante, à des échelles spatiales et temporelles variées. Depuis que Franco Moretti45 a forgé l’expression de lecture distante, celle-ci a connu un engouement, notamment au sein des humanités numériques, mais aussi de sérieuses critiques46. De l’usage et des critiques est ressortie la notion de lecture « multi-échelle » (scalable reading)47 – c’est-à-dire le fait d’imbriquer les différentes échelles de lecture, de ne renoncer ni à la lecture proche, qualitative, ni à la lecture distante –lorsque l’ordinateur et des logiciels « lisent pour nous ». Nous donnerons ici deux types d’exemples de ces dimensions spatio-temporelles des collections : d’abord, les cas de GeoCities, de Mygale.org et du Web yougoslave – lorsque l’espace-temps est clos et que la collecte des données et leur lecture relèvent de l’urgence ou de l’impossibilité ; ensuite, celui du Centenaire de la Grande Guerre, alors que l’espace-temps de cet événement restait ouvert, rendant la collecte possible voire aisée, mais avec des limites importantes.
Dans ses recherches sur GeoCities, en alternant lectures proche et distante, Ian Milligan montre par des visualisations et cartographies de cet espace numérique un type d’agencement des relations sociales48. Créée en 1994, GeoCities est une plateforme populaire d’hébergement de sites web, fondée sur une métaphore géographique manifeste. Les sites web y sont regroupés en neighbourhoods (quartiers) en fonction des sujets traités et des affinités thématiques. Ian Milligan montre comment cet ensemble de sites a permis à de nombreux utilisateurs de tisser des liens au sein d’un Web à l’époque encore balbutiant et parfois intimidant, y compris en construisant des communautés reposant sur l’entraide entre utilisateurs. Mais cette recherche sur GeoCities rappelle aussi indirectement la fragilité des sources nativement numériques : GeoCities est racheté en 1999 par la société Yahoo!, qui décide en 2009 de le fermer puis de l’effacer. S’il est sauvé in extremis par l’Archive team49, de nombreuses plateformes et sites web, notamment avant 2000, n’ont jamais été archivés. Mygale.org était une forme d’équivalent francophone de GeoCities. Ce service, devenu Multimania en 1999, n’est archivé par Internet Archive qu’à partir de 2000. Estimé à 40 000 sites web en 1998 (soit à peu près la moitié des sites web français d’alors)50, Mygale.org puis Multimania est laissé à l’abandon à partir de 2009, lorsque Lycos Europe, devenu son propriétaire, a été liquidé. Au regard des histoires croisées de GeoCities et de Mygale.org, apparaît un espace-temps du web empli d’absences qu’il faut s’efforcer de comprendre, parfois de combler. C’est ce qu’Anat Ben-David a tenté de faire en reconstituant le domaine yougoslave (.yu), disparu avec la fin de la République fédérale de Yougoslavie en 200351.
Les RSNs sont également sujets à des failles spatio-temporelles, mais selon des modalités assez différentes. En effet, les médias sociaux tels que Facebook ou Twitter ont des spécificités fortes en raison des données émises, gigantesques, même en comparaison des archives du web, d’une part ; des modalités de leur archivage, d’autre part52. Les archives institutionnelles du Web collectent certains éléments, mais un chercheur ou une chercheuse peut être amené à constituer son corpus lui-même via les API des RSNs, pour des raisons diverses, qui tiennent à un intérêt pour un sujet spécifique ou/et au souhait d’avoir ses propres données accessibles sur son ordinateur et traitables par des outils choisis par exemple. Si la collecte de Facebook relève plutôt du parcours du combattant, collecter des données sur Twitter est plus aisé, surtout depuis 2021, lorsque la firme californienne a lancé une opération d’ouverture de ses données vis-à-vis des chercheurs et chercheuses53. Une fois l’opération reconnue comme telle par Twitter, il est possible de collecter 10 millions de tweets par mois dans l’ensemble de l’historique de Twitter. Le volume qui peut être acquis nécessite la plupart du temps de faire appel à des méthodologies issues des sciences informatiques (techniques d’apprentissages, machine et deep learning54).
L’une des caractéristiques des tweets moissonnés est de contenir de nombreuses métadonnées, y compris spatiales au sens de géographiques (divers éléments de lieux ou encore la latitude et longitude, si l’utilisateur – cas rare – accepte la géolocalisation), ainsi que des données permettant de reconstituer la position d’un utilisateur de Twitter dans un espace défini, une « twittosphère », et ce notamment par des liens. Ces derniers peuvent être de plusieurs sortes : les liens conversationnels proposés par la plateforme comme les retweets, réponses, likes, ou les liens hypertexte plus classiques renvoyant vers d’autres espaces du Web. Les métadonnées temporelles ont, elles, la particularité de donner la possibilité (théorique) de reconstituer ce qui se dit, les interactions sociales, à la seconde près. Il devient alors possible de saisir très précisément des « vibrations55 ». Dans le cas du Centenaire de la Première Guerre mondiale, la conjugaison des possibilités de collecte de données Twitter et des outils de lecture distante (IRaMuTeQ par exemple) a permis d’observer et d’analyser les temporalités et espaces de la commémoration en ligne56. La temporalité se retrouve dans le nombre de tweets collectés, irrégulier au fil du Centenaire, de 2014 à 2018, et qui se glisse dans le rythme des commémorations officielles. Mais elle se retrouve aussi dans le contenu des tweets, par exemple pour les tweets francophones (Fig. 1 et 2).
Figure 1 – Classification hiérarchique descendante (CHD, méthode Reinert, telle qu’implémentée dans IRaMuTeQ) des tweets francophones du corpus collecté pendant le Centenaire

La CHD (Fig. 157) regroupe des segments de texte – ici, des tweets – dans des classes, selon un raisonnement statistique reposant pour l’essentiel sur la co-occurrence de mots. Les mots affichés (lemmatisés et en bas de casse) sont les lemmes plus pertinents pour chacune des classes. Ainsi, la classe 4, par exemple, regroupe 3,5% des tweets analysés. Les mots les plus pertinents de cette classe (« macron », « président », « hollande », « trump », etc) permettent, avec d’autres fonctionnalités d’IraMuTeQ, d’interpréter le contenu des tweets de cette classe.
Figure 2 - Projection chronologique (par mois) des classes de la CHD
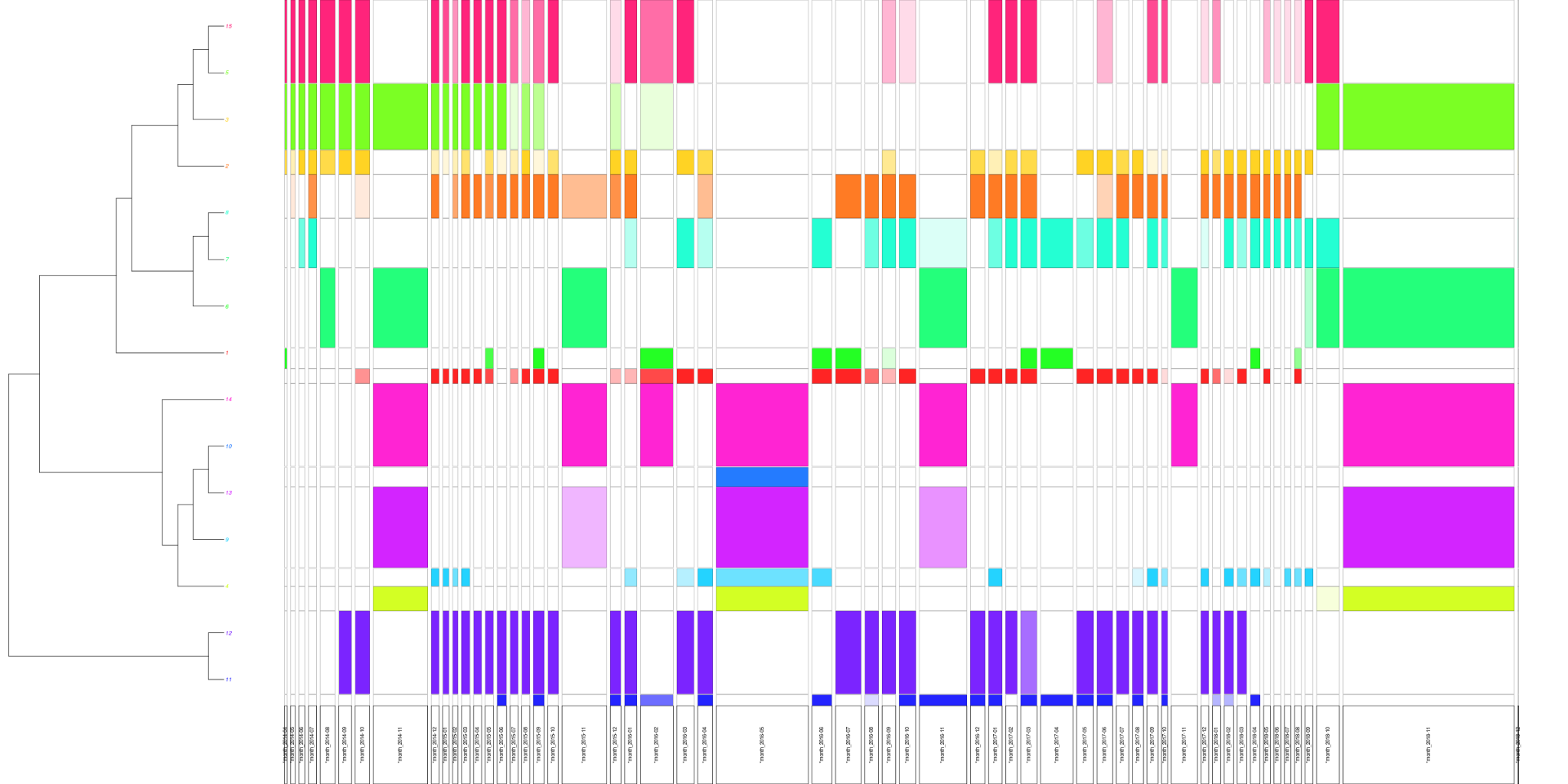
La projection dans le temps des classes de tweets obtenues par la méthode Reinert (Fig. 2) permet par exemple de déduire que l’on ne parle pas du Poilu mort pour la France avec les mêmes mots pendant les grandes commémorations (vocabulaire général de l’hommage) et le reste du temps (hommage à des poilus particuliers), ou que les moments de grandes commémorations (comme les 11 novembre ou, en 2016, la commémoration franco-allemande de Verdun ou franco-britannique de la Somme) apportent toujours leur lot de contestations.
Les relations entre les comptes Twitter peuvent également se traduire dans l’espace, compris ici comme l’agencement des comptes Twitter les uns par rapport aux autres (Fig. 3).
Figure 3 - Réseau des relations (réponses, citation, retweets) du Centenaire de la Grande Guerre
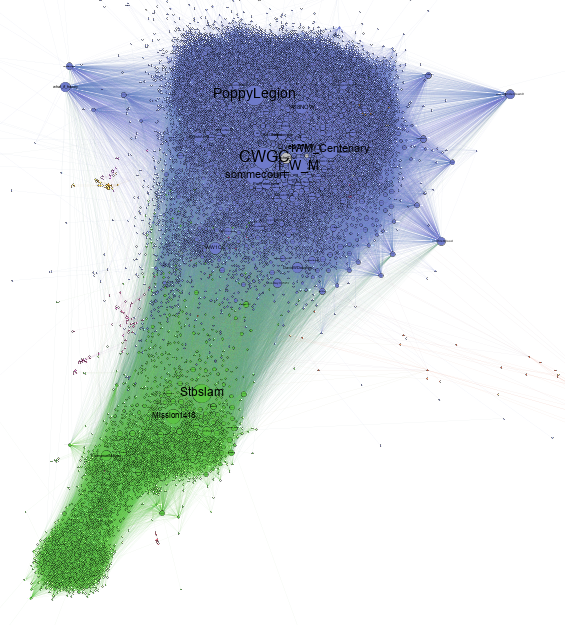
La figure 3 montre ainsi trois espaces : l’un anglophone et majoritaire (en violet), l’autre francophone et structuré pour l’essentiel autour de la Mission du Centenaire (Mission14-18) et du compte de la journaliste Stéphanie Trouillard (en vert, partie supérieure) et le dernier (en vert, partie inférieure) regroupant des comptes ayant pour beaucoup participé aux controverses de mai 2016 autour de la commémoration de Verdun.
Toutefois, l’abondance de métadonnées spatio-temporelles n’est pas synonyme de reconstitution complète d’un espace-temps, car ces métadonnées ne peuvent que reconstituer un espace-temps géré et défini par la plateforme elle-même. Elles ne sont pas relatives à d’autres temporalités, celles de chaque compte Twitter par exemple.
Ces exemples se rejoignent sur certaines lacunes et biais. La volonté de suivre des phénomènes trans-plateformes, comme dans le cas du projet HiVi (A history of online virality)58, va cumuler ces difficultés spatio-temporelles : la viralité, en circulant d’une plateforme à une autre, révèle des asymétries en termes d’archivage (YouTube est très bien archivé par l’Ina mais ce n’est pas le cas dans bien des pays européens, TikTok et Instagram ne sont quasiment pas archivés). Elle pose aussi la question des doublons, nombreux dans le cas des phénomènes viraux, ainsi que des nuances ténues entre les différentes formes que prend un phénomène comme un mème (variation du texte accompagnant une image macro, collage, mash-up), ce qui peut poser des problèmes de recherche. Les phénomènes Internet présentent des temporalités parfois très courtes (pic du Harlem Shake59 en 2013 sur quelques mois), parfois plus longues (stabilité du Rickroll60) et invitent à croiser Web vivant et archivé, ainsi que des fonds et interfaces différents, à l’instar de ceux de la BnF et de l’Ina. À l’instantanéité et au caractère volatile, voire éphémère, des données numériques, répondent donc des temporalités de la recherche plus longues61.
Espace et temps de la recherche
Si l’archivage et les données du patrimoine nativement numérique sont mis au défi de l’espace et du temps, ces derniers sont également à prendre en compte dans le cadre de la recherche scientifique.
Outre les problèmes de maintenance et de durabilité que peuvent poser des collectes effectuées par les chercheurs eux-mêmes (cf. les enjeux des FAIR data62), la question de la contextualisation des données est centrale. L’entreprise collective au sein du projet WARCnet63 de documentation des collectes COVID, qui a permis de réaliser de nombreux entretiens oraux avec des institutions d’archivage (au Danemark, au Luxembourg, en Irlande, en France, en Grande-Bretagne, etc.64), est une réponse à un besoin de contextualisation et de documentation pérenne.
D’autres enjeux se posent en termes d’accès aux données65 et d’outils. Les interfaces, les modes de consultation et les outils de recherche sont aussi mouvants que les périmètres d’archivage du Web. Ainsi l’implémentation d’une recherche plein texte dans les pages d’accueil d’Internet Archive au cours de la décennie 2010 a-t-elle permis de contourner certaines difficultés antérieures de la recherche par une URL précise dans la Wayback Machine. Dans cette dernière, des fonctions de comparaison entre les pages et de visualisation de la structure des sites ont également été ajoutées, tandis que d’autres institutions d’archivage misent de plus en plus sur la fourniture de métadonnées pour une lecture distante des fonds. Des données dérivées telles que l’URL d’un site, son nom de domaine, sa date d’archivage, la nature du fichier (vidéo, texte, audio…) permettent sans entrer dans le contenu d’identifier des tendances (par exemple, une surreprésentation de sites anglophones, gouvernementaux, etc.). Ce mouvement s’amplifie grâce à des initiatives dédiées aux chercheurs comme la récente création du BnF Datalab qui accompagne les chercheurs dans l’exploitation de son patrimoine numérisé ou nativement numérique sous l’angle d’une approche par les données, ou les « datathons » organisés par l’Ina.
La recherche sur des phénomènes transnationaux se heurte quant à elle à la logique spatiale de nombreuses archives du Web, souvent nationales car issues des lois sur le dépôt légal, mais aussi au multilinguisme et aux limitations d’accès aux fonds dans les enceintes des bibliothèques. Seules les métadonnées sont éventuellement exportables, bien qu’elles soient rarement harmonisées d’une archive à l’autre. Le travail sur les métadonnées permet d’amorcer une recherche, mais il est en général insuffisant. Travailler autour de sujets transnationaux implique fréquemment la constitution d’équipes interdisciplinaires multinationales. Le besoin d’approches analytiques complémentaires issues des sciences de l’information, de la sociologie, de l’anthropologie et de l’histoire, par exemple, se conjugue à un besoin de savoir-faire informatique et technique. Intégrer des chercheurs et chercheuses en sciences informatiques – parfois en mathématiques ou physique aussi, comme le rappelle Philippe Rygiel66 – implique des ajustements d’objectifs de recherche, par exemple pour permettre la publication d’articles plus orientés vers les sciences informatiques. Le projet Analysing Web Archives of the COVID Crisis through the IIPC Novel Coronavirus dataset (AWAC2)67 montre ainsi bien les défis qu’engendre une recherche sur un sujet transnational mené par une équipe européenne sur un financement venant d’un autre continent (le Canada). Ce projet de recherche, financé par le programme canadien Archive Unleashed en coopération avec Archive-It (une entreprise non-profit californienne liée à Internet Archive), a pu avoir accès à un corpus d’archives du Web constitué par l’IIPC (International Internet Preservation Consortium) en coopération avec de nombreuses institutions nationales d’archivage du web, et ce via une interface ARCH et les outils développés par l’équipe d’Archive Unleashed. Ces derniers permettent de créer des corpus de données dérivés, plus faciles à utiliser que le corpus d’origine d’un volume de plus de cinq téraoctets. Toutefois, ces jeux de données dérivés restent d’un usage complexe. Ils ont impliqué la mise au point de méthodes de travail issues du monde informatique (utilisation de la plateforme github, écriture de lignes de code au sein de code notebooks permettant la reproductibilité et le partage des analyses ainsi développées), ainsi que l’élargissement de l’équipe à un chercheur en sciences informatiques. La fouille de texte étant un outil central, l’arrivée du collègue informaticien a aussi ajouté comme possible but de recherche la comparaison de différents outils de topic modeling, l’une des techniques au cœur de la fouille de texte. AWAC2 est ainsi au cœur de plusieurs espaces-temps – celui du corpus, croisant des logiques d’archivage nationales et internationales, dont l’équipe n’a pas encore perçu toutes les subtilités ; ceux de cadres de recherche sur deux continents ; ceux de disciplines devant trouver des objets communs de recherche. Ce croisement implique une évolution des méthodes et rythmes de recherche, c’est-à-dire le fait de trouver un espace-temps commun à toutes celles et ceux impliqués dans cette recherche.
Il implique également des accords sur l’accès, la sécurisation, le traitement et l’usage des données qui s’inscrivent dans plusieurs cadres, dont le règlement général de la protection des données (RGPD). Tout chercheur de l’Union européenne manipulant des données massives doit se conformer à cette réglementation, et faire une évaluation préalable des dommages potentiels, notamment sur la préservation de l’anonymat. Certains projets se sont également saisis de ces problématiques sous l’angle éthique, comme le projet Documenting the Now – fortement actif aux côtés du mouvement Black Lives Matter. Bien que le RGPD se soit et ait inspiré de nombreuses législations extra-européennes (le Japon, l’Argentine, la Californie, ou encore l’Uruguay depuis 2008), il ne peut s’appliquer à tous les terrains. En outre, l’encadrement sur les données massives ne peut se contenter d’être juridique, sans infrastructures techniques régulant le stockage et l’exploitation des données. Devant l’influence des GAFAMI, qui repose sur la « prédation de ces traces d’activité, et parfois de données nominatives »68, les problématiques éthiques doivent aussi constituer l’une des priorités méthodologiques du Big Data.
Le travail sur des collectes d’urgence et événements récents met également à jour des temporalités difficilement conciliables. À partir de la mi-mars 2020, le nombre de projets de recherche montés en tant que réponses rapides à la crise sanitaire a été particulièrement important. Cela peut s’expliquer par l’importance de la crise, mais également par son statut : la première crise mondiale de cette ampleur à l’ère des données massives. La temporalité de ces projets de réponse rapide est confrontée à celles de la recherche et de la pérennisation. À ceci s’ajoutent la multiplication des crises (les attentats de 2015 et 2016, la crise sanitaire de 2020, l’agression russe contre l’Ukraine) et la fatigue qui en découle, dont la fatigue informationnelle : le big data est aussi l’ère de la circulation de l’information à haute fréquence et la difficulté, y compris pour la recherche, est d’appréhender ce flux constant, dense, connaissant parfois de brèves mais intenses accélérations69.
Si le but de ces projets a très certainement été de documenter le présent pour le futur, il n’est pas certain que les moyens de leur pérennisation suivent. Comment s’assurer que, dans vingt ans ou plus, ces amas de données puissent encore être compris ? Et comment pérenniser quand l’on change d’université sans pouvoir garder une main sur les recherches menées dans l’institution quittée ? La préservation du Big Data constitue ainsi un enjeu central pour la recherche scientifique, qui doit penser ses infrastructures, ses outils de collecte et de maintenance. En France, les très grandes infrastructures de recherche (TGIR) assurent un cadre depuis une vingtaine d’années en sciences humaines sociales. Pilotées par des comités scientifiques, des TGIR comme Huma-Num70 ou Progedo71 mettent en œuvre des infrastructures numériques pour la valorisation des SHS à l’échelle nationale et européenne, et proposent notamment des plateformes de préservation et de diffusion de données (NAKALA), ou encore des moteurs de recherche (Isidore). La valorisation d’une science participative (principe des wikis), l’accès aux données massives à travers de nouveaux outils (git72) et la production de nouvelles formes de savoir, grâce à l’interopérabilité des plateformes, dénotent un renouvellement épistémologique, organisationnel et méthodologique nécessaire à l’ère du Big Data en SHS. En sociologie notamment, ce renouvellement épistémologique a déjà fait l’objet de publications assez nombreuses73. Il reste néanmoins, et plus particulièrement en histoire, à explorer plus avant.
Conclusion
Ce parcours à travers les temporalités et espaces des traces numériques du Web et des RSNs en trois temps (collecte, collection et recherche) permet de démontrer à la fois la densité temporelle et spatiale des données à l’ère du Big Data, les possibilités ouvertes par une lecture multi-scalaire (scalable reading) pour rendre compte de la granularité spatiale et temporelle au sein de corpus massifs, mais également la profonde illusion de l’exhaustivité.
Que ce soit pour des raisons légales, institutionnelles, scientifiques ou politiques, la préservation et l’exploitation du Big Data se heurte à des problématiques déjà connues avant Internet et le Web – tensions, asymétries, silences et bruits, archivage d’urgence – mais implique aussi, face au poids du présentisme en histoire depuis la fin du XXe siècle74, de repenser nos grilles de lecture pour analyser les sociétés contemporaines, comme l’ont démontré les discussions autour de l’archivage des données à la suite de l’assassinat de George Floyd en 202075.
L’imbroglio spatio-temporel évoqué dans cet article montre les faiblesses comme les formidables atouts qu’offrent les sources nativement numériques pour l’histoire culturelle, ce dont témoignent les exemples convoqués, dans le champ des réactions aux attentats, des sensibilités et expériences de la crise sanitaire, des mémoires et commémorations ou encore des cultures numériques. Penser le temps et l’espace du Big Data implique l’utilisation de matérialités nouvelles, à partir notamment des serveurs de stockage des infrastructures de recherche.
Les sources nativement numériques invitent à des efforts de renouvellement méthodologique et épistémologique pour comprendre nos sociétés contemporaines. Elles engendrent des glissements de l’archive à la donnée, des enjeux de contextualisation encore insuffisamment théorisés – et complexes en raison de la diversité des plateformes, audiences, communautés numériques, formats, archives, et données –, ainsi qu’une interdisciplinarité certaine pour acquérir de nouvelles « habiletés » cognitives et rhétoriques76, appréhender de nouvelles « communautés imaginées »77 et tirer pleinement bénéfice des multiples échelles spatiales et temporelles.